HappyHorse-1.0: The AI Video Model That Topped Every Leaderboard
By AI Workflows Team · April 11, 2026 · 10 min read
HappyHorse-1.0 appeared anonymously, topped every AI video leaderboard with Elo 1,415, then Alibaba claimed it. Here's the full story: architecture, benchmarks, and what it means for AI video in 2026.
TL;DR: HappyHorse-1.0 is a 15-billion-parameter AI video generation model built by Alibaba's ATH (Alibaba Token Hub) unit, via its internal Future Life Lab (Taotian Group). It appeared anonymously on the Artificial Analysis leaderboard on April 7, 2026, and within days seized the #1 spot in both text-to-video (Elo 1,357) and image-to-video (Elo 1,414) — beating ByteDance's Seedance 2.0 and Kling 3.0. Alibaba officially claimed the model on April 10, 2026, and BABA stock jumped more than 4% intraday. A public API is scheduled to open April 30, 2026. Model weights are promised as open-source but not yet released.
Table of Contents
- What Is HappyHorse-1.0?
- The Mystery: How It Appeared and Was Revealed
- Who Built HappyHorse? Alibaba, Taotian & Future Life Lab
- Benchmark Results: The Numbers Behind #1
- Technical Architecture Deep Dive
- Key Capabilities
- HappyHorse vs. Competitors
- Availability & Pricing
- Why This Matters: Strategic Context
- FAQ
- Sources & References
What Is HappyHorse-1.0? {#what-is-happyhorse}
HappyHorse-1.0 is a multimodal AI video generation model that jointly produces video and synchronized audio from either a text prompt or an input image. Unlike the vast majority of competing systems — which generate silent video and rely on a separate audio post-processing stage — HappyHorse natively synthesizes dialogue, ambient sound, and Foley effects within a single forward pass.
According to the Artificial Analysis Video Arena, HappyHorse-1.0 currently holds the #1 position on both the image-to-video and text-to-video leaderboards (no-audio category), with an Elo score of 1,415 (I2V) and 1,357 (T2V) as of April 2026. These scores are derived from blind pairwise comparisons by real users — not cherry-picked by the developer.
The model supports seven languages for lip-synchronized audio generation: Mandarin Chinese, Cantonese, English, Japanese, Korean, German, and French. Output resolution reaches 1080p, and the model claims inference of approximately 38 seconds for a 1080p clip on a single H100 GPU.
What set it apart from its debut was not just the performance — it was the mystery. The model showed up with no name brand, no press release, and no company attribution. The AI community spent several days speculating before Alibaba revealed itself as the creator.
The Mystery: How HappyHorse Appeared and Was Revealed {#the-mystery}
In early April 2026, a new model entry appeared on the Artificial Analysis Video Arena leaderboard under the name "happyhorse-ai/happyhorse-1.0" with no accompanying company, no technical paper, and no press outreach. Within days, it had climbed to the top of blind rankings in multiple categories.
The name alone triggered immediate speculation. Reddit threads and X posts debated whether it was:
- A pseudonymous spin-off of Alibaba's own Wan series (Wan 2.6 had scored an Elo of ~1,189)
- An optimized version of Sand.ai's daVinci-MagiHuman model
- A secret project by a former ByteDance team (some noted the Kling AI pedigree of the apparent lead)
- A joint venture between unnamed Chinese research labs
The mystery was deepened by a Hugging Face model card at happyhorse-ai/happyhorse-1.0 that listed GitHub and weights links as "Coming Soon," and an official site that displayed no creator information. The anonymous launch pattern has become a deliberate strategy in the Chinese AI ecosystem — companies test real-world reception before attaching corporate brand risk. This mirrors how Xiaomi's "Hunter Alpha" model was released anonymously before attribution.
On April 10, 2026 — three days after the leaderboard domination went viral — Alibaba revealed itself as the creator via a newly created X (Twitter) account. Bloomberg and CNBC reported the confirmation simultaneously. According to CNBC and Bloomberg, the model is still in internal beta testing, with a public API scheduled to open on April 30, 2026.
The market reacted immediately: BABA stock rose more than 4% intraday and closed up 2.12% at the Hong Kong exchange on April 10 — a notable bump for a company of Alibaba's size triggered by a single model reveal.
"The anonymous launch was intentional — the team wanted the model to be judged by its output quality before anyone attached corporate expectations to it." — unnamed source cited by Bloomberg, April 10, 2026
Who Built HappyHorse? Alibaba ATH, Taotian & Future Life Lab {#who-built}
HappyHorse-1.0 was built by Future Life Lab, a research team operating under Taotian Group (Alibaba's domestic e-commerce arm, encompassing Taobao and Tmall). The project sits organizationally within ATH — Alibaba Token Hub — a newly formed Alibaba business group focused on AI-native consumer products, separate from Alibaba Cloud's AI division (which owns the Qwen LLM and Wan video series).
This organizational nuance matters: ATH is consumer-facing, not enterprise cloud — which points toward a different product roadmap than Alibaba's other AI investments.
The project is led by Zhang Di, who brings a notable pedigree in AI video:
- Former VP of Technology at Kuaishou (one of China's largest short-video platforms)
- Former technical lead of Kling AI, the video generation product at ByteDance that ranked #5 globally with Kling 3.0 before HappyHorse debuted
- Rejoined Alibaba in November 2025, leading the months-long sprint that produced HappyHorse
Zhang Di's background explains the model's emphasis on human-centric generation: facial performance, body motion, lip synchronization, and dialogue are treated as first-class outputs rather than post-processing additions. This reflects the priorities of a team that spent years building tools for short-video creators on consumer platforms.
The Taotian connection is strategically significant. Taotian runs commerce and live-streaming products where high-quality, lip-synced video generation at scale has obvious product-market fit — from AI-generated product videos to live commerce hosts.
Benchmark Results: The Numbers Behind #1 {#benchmarks}
All rankings below are from the Artificial Analysis Video Arena, which uses an Elo rating system derived from blind pairwise user votes — meaning human evaluators compare two videos generated from the same prompt and select the better one, without knowing which model produced which output.
Image-to-Video Leaderboard (No Audio)
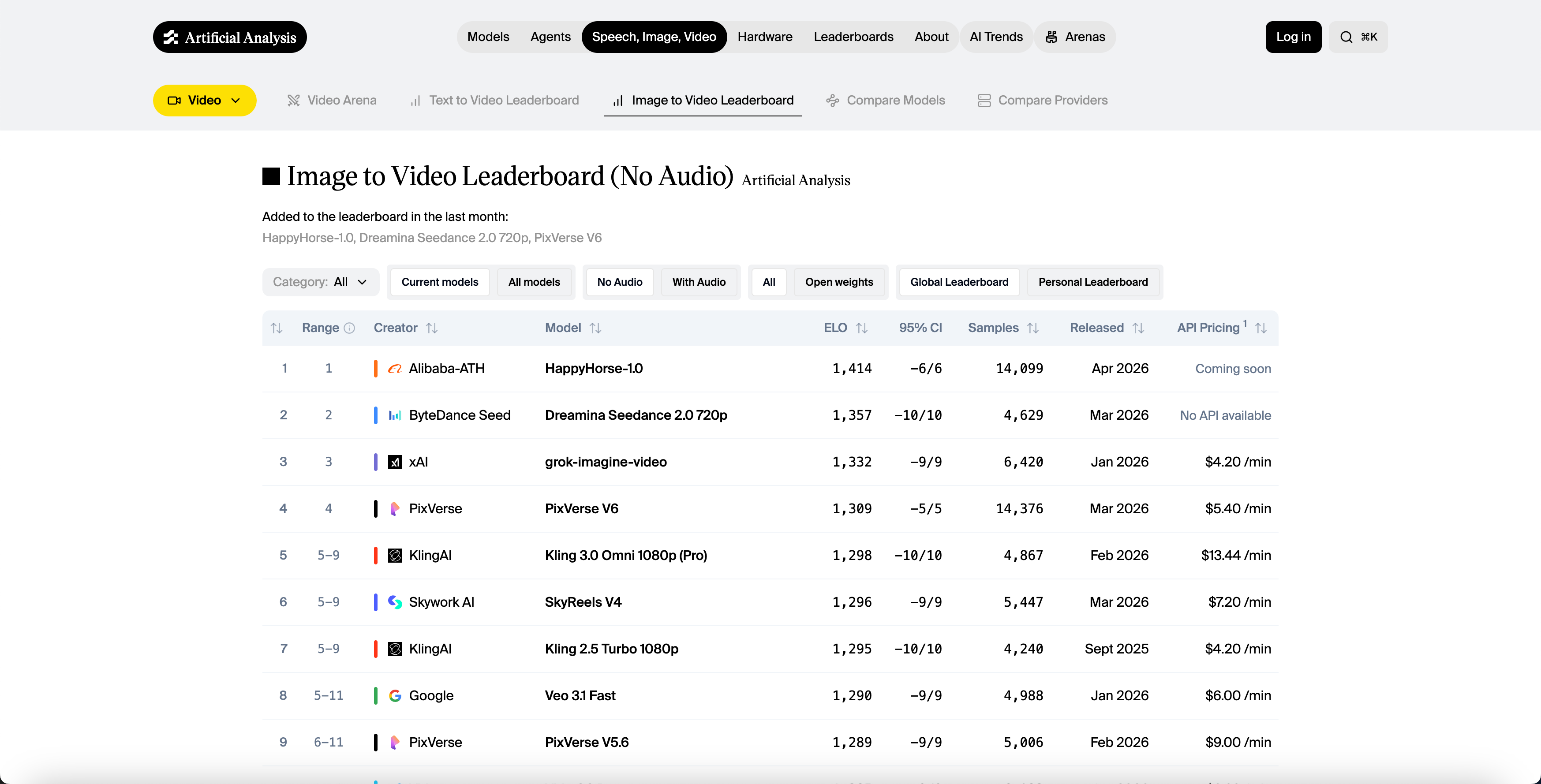
| Rank | Model | Elo Score | Samples | API Pricing | Developer |
|---|---|---|---|---|---|
| 🥇 1 | HappyHorse-1.0 | 1,414 | 14,099 | Coming soon | Alibaba-ATH |
| 🥈 2 | Dreamina Seedance 2.0 720p | 1,357 | 4,629 | No API | ByteDance Seed |
| 🥉 3 | grok-imagine-video | 1,332 | 6,420 | $4.20/min | xAI |
| 4 | PixVerse V6 | 1,309 | 14,376 | $5.40/min | PixVerse |
| 5 | Kling 3.0 Omni 1080p (Pro) | 1,298 | 4,867 | $13.44/min | KlingAI |
| 6 | SkyReels V4 | 1,296 | 5,447 | $7.20/min | Skywork AI |
| 7 | Veo 3.1 Fast | 1,290 | 4,988 | $6.00/min |
Source: Artificial Analysis Video Arena, April 2026
Text-to-Video Leaderboard (No Audio)
| Rank | Model | Elo Score | Developer |
|---|---|---|---|
| 🥇 1 | HappyHorse-1.0 | 1,357 | Alibaba (Taotian) |
| 🥈 2 | Dreamina Seedance 2.0 | 1,273 | ByteDance Seed |
| 3 | SkyReels V4 | 1,245 | Skywork |
| 4 | Kling 3.0 Pro | 1,243 | KlingAI |
| 5 | PixVerse V6 | 1,240 | PixVerse |
With-Audio Leaderboard — The One Caveat
In the with-audio categories, HappyHorse finishes #2 behind Seedance 2.0:
- T2V with audio: Seedance 2.0 (1,219) vs. HappyHorse (1,205) — a 14-point gap
- I2V with audio: Nearly tied, within 1 Elo point
This is notable because HappyHorse was explicitly engineered for native audio synthesis. The slight deficit to Seedance 2.0 in the with-audio category may reflect Seedance 2.0's more sophisticated multi-reference audio control (up to 3 audio inputs per generation) versus HappyHorse's single-pass unified approach.
What does a 60-point Elo gap mean in practice? According to Elo theory, a 60-point gap corresponds to approximately a 58–59% win rate in head-to-head blind comparisons. That means if you ran 100 blind A/B tests between HappyHorse and Seedance 2.0 on text-to-video, HappyHorse would win approximately 58–59 of them. Users can consistently perceive the difference — this is not a marginal statistical gap.
A note on sample stability: As of April 2026, HappyHorse-1.0 has accumulated 14,099 samples on the Artificial Analysis arena — actually more than Seedance 2.0's 4,629 and PixVerse V6's 14,376. Its 95% confidence interval of ±6 Elo points is tighter than most competitors (Seedance 2.0 sits at ±10). This means the #1 ranking reflects a statistically robust signal, not a thin early lead.
Technical Architecture Deep Dive {#architecture}
HappyHorse-1.0's architecture departs meaningfully from the DiT (Diffusion Transformer) + cross-attention designs used by most competing models.
Unified Single-Stream Transformer
The model uses a 40-layer self-attention Transformer in a "sandwich" configuration:
- Layers 1–4 & 37–40 (8 total): Modality-specific projection layers — separate learned projections for text tokens, image latents, video latents, and audio tokens
- Layers 5–36 (32 total): Fully shared parameters across all modalities — text, image, video, and audio tokens attend to each other without any cross-attention gating
There is no cross-attention mechanism at all. In conventional video generation models, text conditioning is typically injected via cross-attention layers where video tokens attend to text encoder outputs. HappyHorse instead places all modalities — text, image latents, video frames, and audio spectrograms — into a single flat token sequence and lets the self-attention mechanism handle all modality fusion natively.
No Explicit Timestep Embeddings
Most diffusion models inject a learned timestep embedding to tell the network how much noise is present in the input. HappyHorse infers the denoising state directly from the noise level of the input latents — eliminating a whole class of hyperparameter tuning and enabling cleaner distillation.
DMD-2 Distillation → 8-Step Inference
The model uses Distribution Matching Distillation (DMD-2) to compress sampling from the typical 25–50 steps down to 8 denoising steps with no classifier-free guidance (CFG). This is aggressive distillation — most production models at this quality tier require 20–50 steps. The 8-step inference gives:
- ~2 seconds for a 5-second 256p clip
- ~38 seconds for a 5-second 1080p clip on an H100 GPU
Learned Scalar Gates for Multimodal Stability
One of the hardest engineering problems in joint multimodal training is gradient instability: modalities can destructively interfere during backpropagation, causing training collapse or one modality dominating others. HappyHorse addresses this with learned scalar gates on each attention head that selectively dampen harmful gradient flows between modality streams, stabilizing joint training without needing separate training phases per modality.
Parameter Count & Hardware Requirements
Secondary sources cite approximately 15 billion parameters total, though this has not been independently confirmed through public weights inspection. The architecture's parameter sharing across the 32 middle layers means per-modality parameter efficiency is significantly higher than a naive multi-tower design.
Recommended inference hardware: H100 or A100 GPU with at least 48GB VRAM. A single H100 produces a 5-second 1080p clip in approximately 38 seconds.
Key Capabilities {#capabilities}
Native Multilingual Audio Synthesis
HappyHorse generates dialogue, ambient sound, and Foley effects in a single pass, natively supporting:
| Language | Lip-Sync Support |
|---|---|
| Mandarin Chinese | ✅ |
| Cantonese | ✅ |
| English | ✅ |
| Japanese | ✅ |
| Korean | ✅ |
| German | ✅ |
| French | ✅ |
This eliminates the multi-stage pipeline (generate silent video → generate audio → align lip-sync) that most competitors — including Runway and HeyGen for talking-head use cases — still use, reducing latency and synchronization artifacts.
Human-Centric Generation
The team, drawing on years of short-video platform experience, specifically optimized for:
- Facial performance consistency across frames
- Speech coordination (jaw movement, tongue visibility, lip shape accuracy)
- Body motion naturalness
- Multi-character scenes with independent motion
1080p Output
Native 1080p resolution generation — competitive with the top tier of commercial video APIs.
HappyHorse-1.0 vs. Competitors {#comparison}
Here is how HappyHorse-1.0 compares to the current top alternatives for production and creative use cases as of April 2026:
| Model | T2V Elo | I2V Elo | Native Audio | API Available | Cost |
|---|---|---|---|---|---|
| HappyHorse-1.0 | 1,357 | 1,414 | ✅ (7 lang) | ⏳ Apr 30 | Coming soon |
| Dreamina Seedance 2.0 | 1,273 | 1,357 | ✅ (multi-ref) | ⚠️ Limited (CapCut) | N/A |
| Kling 3.0 Pro | 1,243 | 1,298 | ✅ (dual) | ✅ | $13.44/min |
| SkyReels V4 | 1,245 | 1,296 | ⚠️ | ✅ | $7.20/min |
| PixVerse V6 | 1,240 | 1,309 | ⚠️ | ✅ | $5.40/min |
| grok-imagine-video | — | 1,332 | ❌ | ✅ | $4.20/min |
| Veo 3.1 Fast (Google) | — | 1,290 | ❌ | ✅ | $6.00/min |
HappyHorse vs. Seedance 2.0
Seedance 2.0 (ByteDance Seed) is HappyHorse's closest rival on the benchmarks. Key differences:
- Quality floor: HappyHorse leads by 57–84 Elo points in no-audio categories; Seedance 2.0 leads by 14 points in T2V with audio
- Multi-reference control: Seedance 2.0 supports up to 9 image inputs, 3 video clips, and 3 audio files per generation — significantly more compositional control for complex productions
- Availability: Both models lack public APIs as of April 2026, but Seedance 2.0 has a limited rollout inside CapCut in 7 markets (Brazil, Indonesia, Malaysia, Mexico, Philippines, Thailand, Vietnam). Note: ByteDance paused wider Seedance 2.0 deployment due to copyright disputes with major Hollywood studios and streaming platforms
- Architecture: Seedance 2.0 uses a more conventional DiT approach with cross-attention; HappyHorse's unified transformer is architecturally novel
HappyHorse vs. Kling 3.0
Kling AI (from KlingAI, where Zhang Di previously led development) is the strongest option if you need to ship today:
- API access: Kling 3.0 Pro is available via API at ~$13.44/minute of video — production-ready
- Multi-character: Kling 3.0's strongest differentiator is multi-prompt, multi-character generation with different instructions for different scene segments
- 4K output: Kling 3.0 supports native 4K; HappyHorse currently caps at 1080p
- Quality gap: HappyHorse outperforms Kling 3.0 by 114 Elo points in T2V (no audio) and 116 points in I2V — a substantial margin that reflects clearly visible quality differences in blind tests
The Practical Takeaway
Based on the April 2026 data:
- Best blind-test quality: HappyHorse-1.0 (but not yet accessible)
- Best accessible quality: Kling 3.0 Pro (API available, ~$13.44/min)
- Best value accessible: PixVerse V6 (~$5.40/min, Elo 1,240–1,310)
- Best audio control for complex productions: Seedance 2.0 (limited access)
Availability & Pricing {#availability}
As of April 11, 2026, HappyHorse-1.0 remains inaccessible for production use:
| Access Point | Status |
|---|---|
| Public API | ⏳ Scheduled April 30, 2026 |
| Internal beta | ✅ Active (per Alibaba, April 10) |
| Model weights | ❌ Not yet available |
| GitHub repo | ⚠️ "Coming Soon" |
| HuggingFace model card | ⚠️ "Coming Soon" |
| Pricing | ⚠️ Not announced |
April 30, 2026 API launch is the date to watch. Alibaba confirmed this during the model reveal. If the date holds, HappyHorse will transition from a benchmark story to a production-accessible tool within weeks.
On open-source: the official site claims "everything is open" and the Barchart press release announced weights as already released — but as of April 10, independent reviewers confirmed both GitHub and HuggingFace links still show "Coming Soon" placeholder pages. The open-source community flagged this discrepancy. Treat the open-weight release as imminent but not yet delivered.
For builders today: If your project requires a video generation pipeline right now, look at Kling 3.0 Pro or PixVerse V6 for API access. If you can wait 2–3 weeks, the April 30 HappyHorse API launch — and potentially simultaneous weights release — is worth waiting for given the quality lead.
Why This Matters: Strategic Context {#context}
The Anonymous Launch Strategy
HappyHorse is the most high-profile example yet of what is becoming a standard playbook for Chinese AI labs: release a model anonymously onto a public arena leaderboard, let it accumulate organic wins through blind user comparisons, and reveal the company identity only after the performance story is established.
This strategy is rational: it separates quality signal from brand signal, allowing the model to be judged purely on output before geopolitical, regulatory, or competitive framing colors the reception. According to reporting by Heise Online, this mirrors Xiaomi's earlier approach with "Hunter Alpha."
Power Vacuum After OpenAI's Sora Discontinuation
OpenAI discontinued Sora in early 2026, leaving a significant gap in the high-end video generation market. Chinese developers — ByteDance (Seedance), KlingAI, PixVerse, and now Alibaba (HappyHorse) — have been the primary beneficiaries. The fact that four of the top five positions on the Artificial Analysis leaderboard are held by Chinese-developed models reflects a period of rapid capability catch-up that has now become a capability lead in video generation specifically.
Open-Weight Commitment
HappyHorse's commitment to open-source release would make it the highest-performing openly available video generation model by a substantial margin if the weights materialize as described. For the open-source AI video community, this is the most anticipated release since Wan 2.6 — with a significantly higher quality ceiling.
The Taotian-Commerce Angle
Future Life Lab's home within Taotian (Taobao + Tmall) is a strong signal about the model's long-term commercial roadmap. E-commerce product video generation, AI-powered live-streaming hosts, and multilingual ad localization are all applications where a natively multilingual, human-centric video model with fast inference has immediate product-market fit at Alibaba's scale. Expect the commercial API to be oriented toward these workflows when it launches.
FAQ {#faq}
What is HappyHorse-1.0?
HappyHorse-1.0 is a 15-billion-parameter AI video generation model developed by Alibaba's Future Life Lab (Taotian Group). It is currently ranked #1 on the Artificial Analysis Video Arena for both text-to-video (Elo 1,357) and image-to-video (Elo 1,414), using a unified single-stream Transformer architecture that jointly generates video and audio in a single pass.
Is HappyHorse-1.0 from Alibaba?
Yes. Alibaba confirmed on April 10, 2026, that HappyHorse-1.0 was developed by the Future Life Lab team within its Taotian Group, led by Zhang Di — former VP of Kuaishou and former technical lead of Kling AI at ByteDance.
Is HappyHorse-1.0 open source?
Not yet, but the development team has confirmed full open-source release with public weights is coming soon via GitHub and HuggingFace. As of April 2026, both links display "Coming Soon" and no weights have been released.
How does HappyHorse compare to Sora?
OpenAI discontinued Sora in early 2026. At its peak, Sora scored significantly lower on the Artificial Analysis leaderboard than HappyHorse-1.0. HappyHorse represents the current state-of-the-art in blind user preference testing.
Why did HappyHorse launch anonymously?
The model appeared on the Artificial Analysis leaderboard without company attribution as a deliberate strategy to let performance data establish its reputation before corporate branding was attached. This "mystery model" approach allows quality to drive adoption rather than marketing spend or brand association. Alibaba officially revealed its involvement on April 10, 2026.
Can I use HappyHorse-1.0 today?
Not yet in full production. As of April 11, 2026, the model is in internal beta. Alibaba has confirmed a public API launch on April 30, 2026. Model weights have been promised as open-source but are not yet downloadable (GitHub and HuggingFace links show "Coming Soon"). For production use right now, Kling 3.0 Pro (API available, $13.44/min) or PixVerse V6 ($5.40/min) are the highest-quality accessible alternatives. Check back around April 30 for the API launch.
What languages does HappyHorse support?
HappyHorse-1.0 natively supports lip-synchronized audio synthesis in seven languages: Mandarin Chinese, Cantonese, English, Japanese, Korean, German, and French.
What happened to Alibaba's stock when HappyHorse was revealed?
Alibaba Group (NYSE: BABA) stock rose more than 4% intraday on April 10, 2026 — the day of the official reveal — and closed up approximately 2.12% at the Hong Kong exchange. The market reaction reflected investor enthusiasm for Alibaba's continued push into generative AI following prior successes with the Qwen LLM series.
How does HappyHorse's architecture differ from other AI video models?
Most competing models use a DiT (Diffusion Transformer) architecture with cross-attention for text conditioning — text tokens condition video generation via separate cross-attention layers. HappyHorse uses a unified single-stream Transformer where text, image, video, and audio tokens are placed in one flat sequence and attend to each other via standard self-attention, with no cross-attention at all. This architectural choice enables native joint audio-video synthesis and uses DMD-2 distillation to reduce sampling to just 8 steps.
Sources & References {#sources}
- Alibaba just revealed it's behind a viral AI video model dominating leaderboards — CNBC, April 10, 2026
- Stealth Alibaba Video AI Model Tops Global Ranking on Debut — Bloomberg, April 10, 2026
- Artificial Analysis Video Arena — Image-to-Video Leaderboard
- Happy Horse: Alibaba's secret AI video model storms the benchmarks — Heise Online
- What Is HappyHorse-1.0? The Mystery #1 AI Video Model — WaveSpeedAI Blog
- HappyHorse model decryption — Apiyi.com Blog
- HappyHorse-1.0 Tops AI Video Rankings, Surpassing Seedance 2 — Phemex News
- Alibaba reveals it's behind viral 'Happy Horse' AI model — Seeking Alpha
- Alibaba's HappyHorse tops Seedance, China's race for AI talent — South China Morning Post
- Alibaba Token Hub Is Behind Viral AI Video Model HappyHorse — Yicai Global
- Alibaba confirms HappyHorse belongs to its ATH unit — TechNode
- Is HappyHorse-1.0 Open Source? What We Can Verify — WaveSpeedAI Blog
- Why Is HappyHorse-1.0 Suddenly #1 on Video Leaderboard? — WaveSpeedAI Blog