GPT-5.5 Review: Benchmarks, Agentic Capabilities & Real-World Verdict (2026)
By AI Workflows Team · April 25, 2026 · 14 min read
GPT-5.5 launches April 23, 2026 with 82.7% on Terminal-Bench 2.0, native omnimodal architecture, and doubled API pricing ($5/$30 per 1M tokens). We break down every benchmark, the Claude Opus 4.7 head-to-head, and what real users actually think.
TL;DR {#tldr}
OpenAI shipped GPT-5.5 on April 23, 2026 — six weeks after GPT-5.4 — with state-of-the-art results on 14 benchmarks, native omnimodal architecture, and a sharply upgraded agentic computer-use stack. The headline numbers are real: 82.7% on Terminal-Bench 2.0, 78.7% on OSWorld-Verified, and 74.0% on long-context retrieval at 1M tokens. But the API price doubled (from $2.50/$15 to $5/$30 per million tokens), and real users are divided — some call it a breakthrough in autonomous task completion, others say it feels less useful for everyday writing than GPT-4 era models. Here's the full breakdown.
What Is GPT-5.5? {#what-is-gpt-5-5}
GPT-5.5 is OpenAI's latest frontier model, released on April 23, 2026, to Plus, Pro, Business, and Enterprise subscribers through ChatGPT and Codex. The API version followed on April 24. A more powerful tier, GPT-5.5 Pro, is available to Pro, Business, and Enterprise customers at significantly higher pricing.
OpenAI describes the model as "the next step toward a new way of getting work done on a computer" — deliberately positioning it not as a chatbot upgrade but as an autonomous agent capable of operating software, navigating interfaces, and moving across tools until a task is finished.
The architecture is natively omnimodal: text, images, audio, and video are processed in a single unified system rather than stitched together from separate specialist models. This is a meaningful departure from the modular approach of earlier GPT generations, and it's what enables the computer-use capabilities that define this release.
According to OpenAI's system card, GPT-5.5 reaches state-of-the-art on 14 benchmarks — compared to 4 for Claude Opus 4.7 (released April 16, 2026) and 2 for Google Gemini 3.1 Pro.
What's New in GPT-5.5 {#whats-new}
Agentic Computer Use {#agentic-computer-use}
The most significant capability addition is computer use at scale. When combined with Codex, GPT-5.5 can see what's on screen, click, type, navigate interfaces, and move between applications with stated precision. OpenAI scored 78.7% on OSWorld-Verified — a benchmark that evaluates whether a model can operate real desktop and browser environments autonomously.
This matters for developers building AI agent workflows because it moves the capability from "tool calling with structured outputs" to "actually operating a computer the way a human contractor would."
Native Omnimodal Processing {#omnimodal}
Unlike GPT-5.4, which routed modalities through separate internal pipelines, GPT-5.5 processes text, image, audio, and video in a unified architecture. The practical benefit: complex tasks that mix data types — analyzing a screen recording while writing code to fix what's shown — no longer suffer from the latency and context-loss of modality hand-offs.
Long-Context Retrieval Leap {#long-context}
On the MRCR v2 benchmark at 512K–1M tokens, GPT-5.5 scores 74.0% — a jump from GPT-5.4's baseline performance and dramatically ahead of Claude Opus 4.7's 32.2% at the same context length. At 256K–512K, GPT-5.5 reaches 87.5% versus Opus 4.7's 59.2%.
For developers working with large codebases, extended research pipelines, or enterprise document processing, this is the clearest practical win.
Token Efficiency {#token-efficiency}
OpenAI claims GPT-5.5 is approximately 72% more token-efficient on equivalent tasks compared to GPT-5.4. This is the core justification for doubling the per-token price: the model reaches higher-quality outputs with fewer tokens and fewer retries, so actual cost-per-task increases by roughly 20% rather than 100%.
Independent testing by LLM-Stats broadly confirms this — though the efficiency gain varies significantly by task type, with structured extraction tasks seeing the greatest benefit.
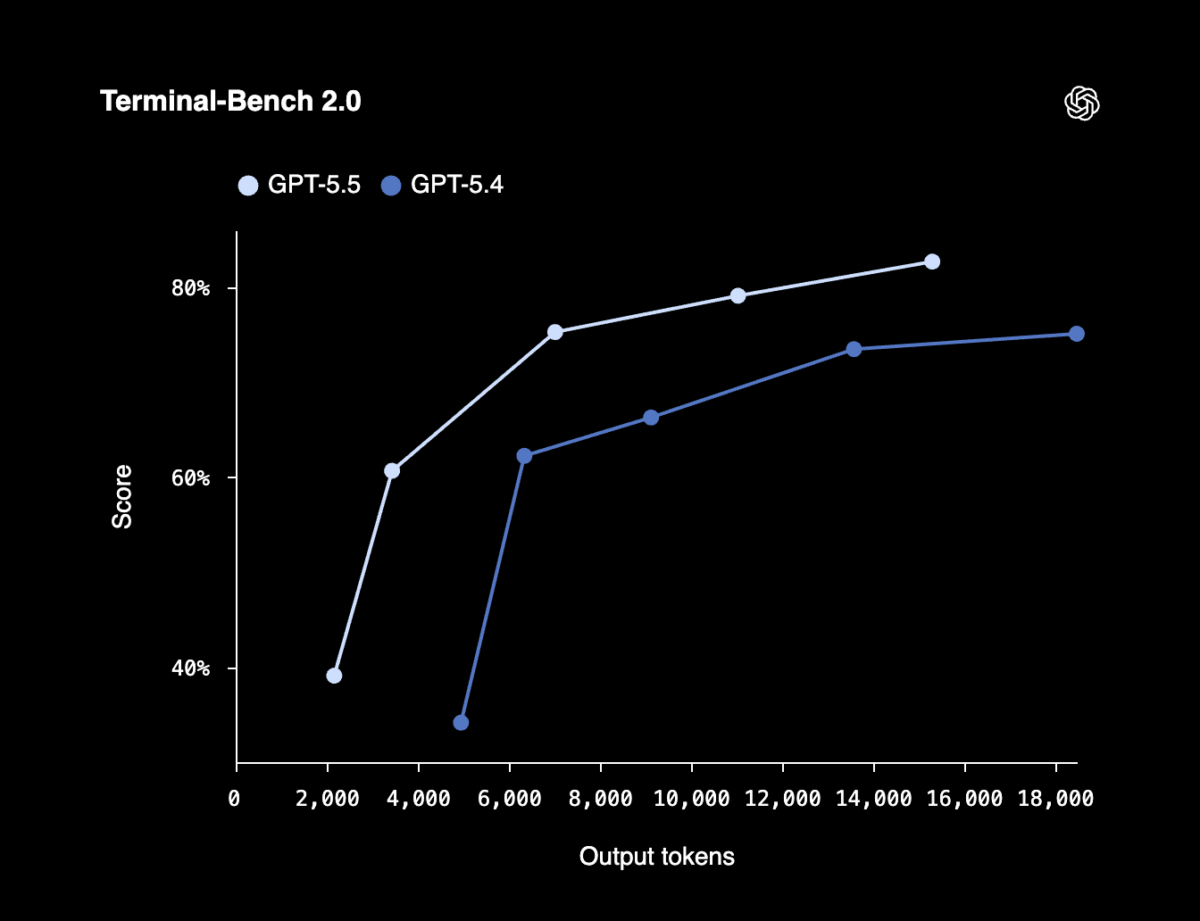
Benchmark Deep Dive {#benchmarks}
Here's the complete benchmark picture from OpenAI's release documentation and independent evaluations:
Core Agentic Benchmarks
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | What It Measures |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | Complex command-line workflows with tool coordination |
| OSWorld-Verified | 78.7% | — | 78.0% | Autonomous desktop/browser environment operation |
| GDPval | 84.9% | — | — | Agent performance across 44 occupations |
| Tau2-bench Telecom | 98.0% | — | — | Complex customer-service multi-step workflows |
| Expert-SWE | 73.1% | — | — | Expert-level software engineering tasks |
| GeneBench | 25.0% | — | — | Genetics and life sciences analysis |
| BixBench | 80.5% | — | — | Bioinformatics task completion |
| CyberGym | 81.8% | — | — | Cybersecurity challenge performance |
Long-Context Retrieval
| Context Range | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 512K–1M tokens | 74.0% | 32.2% |
| 256K–512K tokens | 87.5% | 59.2% |
Where Claude Opus 4.7 Wins
| Benchmark | GPT-5.5 | Claude Opus 4.7 | What It Measures |
|---|---|---|---|
| SWE-Bench Pro | 58.6% | 64.3% | Real GitHub issue resolution |
| MCP Atlas | 75.3% | 79.1% | Multi-tool orchestration reliability |
The pattern is clear: GPT-5.5 leads on agentic task execution and long-context retrieval; Claude Opus 4.7 leads on code quality in realistic development scenarios and multi-model tool coordination. According to Beam AI's head-to-head analysis, the models are "not competing on the same axis — they're optimized for fundamentally different workflows."
Pricing Breakdown {#pricing}
| Tier | Input | Output | Context | Availability |
|---|---|---|---|---|
| GPT-5.5 | $5 / 1M tokens | $30 / 1M tokens | 1M tokens | Plus, Pro, Business, Enterprise |
| GPT-5.5 Pro | $30 / 1M tokens | $180 / 1M tokens | 1M tokens | Pro, Business, Enterprise |
| GPT-5.4 (prev.) | $2.50 / 1M tokens | $15 / 1M tokens | 1M tokens | Still available |
| Claude Opus 4.7 | $5 / 1M tokens | $25 / 1M tokens | 1M tokens | All tiers |
The doubling of GPT-5.5's base API price — from $2.50 to $5 input, $15 to $30 output — is the most contentious aspect of this release. OpenAI's stated position is that 72% token efficiency means real-world cost increases are closer to 20%.
For teams running high-volume agentic pipelines, this math matters: at 72% token reduction, a task that previously cost $1.00 with GPT-5.4 now costs approximately $0.84 with GPT-5.5. But that efficiency gain assumes tasks where GPT-5.5 is significantly more capable — simple retrieval or generation tasks may see the full price increase without the efficiency offset.
Claude Opus 4.7, at $5/$25 vs GPT-5.5's $5/$30, is 17% cheaper on output tokens and maintains competitive SWE-Bench scores for code-heavy workloads. For teams doing AI code development workflows, this pricing delta compounds quickly.
GPT-5.5 vs Claude Opus 4.7: Full Head-to-Head {#gpt-vs-claude}
Both models shipped within a week of each other (Opus 4.7 on April 16, GPT-5.5 on April 23) and both carry 1M-token context windows with extended thinking-style reasoning. But the positioning differs fundamentally.
| Dimension | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Agentic coding (Terminal-Bench 2.0) | ✅ 82.7% | 69.4% |
| Computer use (OSWorld-Verified) | ✅ 78.7% | 78.0% |
| Real codebase issue resolution (SWE-Bench Pro) | 58.6% | ✅ 64.3% |
| Multi-tool orchestration (MCP Atlas) | 75.3% | ✅ 79.1% |
| Long-context retrieval (1M tokens) | ✅ 74.0% | 32.2% |
| Output price per 1M tokens | $30 | ✅ $25 |
| Native computer use | ✅ Yes | Partial |
| Architecture | Unified omnimodal | Modular |
Recommended routing, per MindStudio's April 2026 comparison:
- GPT-5.5: Agentic tasks, computer use, long-document retrieval, multi-step terminal workflows
- Claude Opus 4.7: Code review, GitHub issue resolution, MCP tool chains, cost-sensitive output-heavy tasks
- Cheaper models (GPT-5.4 mini / Claude Haiku 4.5): Anything else
If you're building on OpenAI Codex or Claude Code, the routing decision matters more than ever. Neither model dominates end-to-end. For a deeper look at Opus 4.7's strengths, see our Claude Opus 4.7 review.
What Real Users Are Saying {#user-reactions}
The reception has been sharply divided — and the division itself tells a story.
The Impressed Camp
Developers testing GPT-5.5 on agentic coding tasks report measurable improvements. The 13-point gap on Terminal-Bench 2.0 over Claude Opus 4.7 (82.7% vs 69.4%) translates to real differences in multi-step terminal workflows that require planning, iteration, and tool coordination. Per VentureBeat's April 24 coverage, GPT-5.5 "narrowly beats Anthropic's Claude Mythos Preview" on complex agent tasks.
Security researchers at The New Stack noted that the model's computer-use capabilities introduce new threat vectors, suggesting the capability is real enough to warrant security analysis — itself a signal that it's not vaporware.
The Skeptical Camp
The skepticism is real and structurally familiar. According to IEEE Spectrum, OpenAI is navigating what analysts are calling "the trough of disillusionment" — a phase where each GPT increment, however technically sound, struggles to generate the qualitative leap users have been trained to expect.
Developer Kieran Klassen put it bluntly: "OpenAI's GPT-5.5 is very good, but it seems like something that would have been released a year ago."
The NxCode analysis captures a recurring complaint: GPT-5.x models optimize for reasoning benchmarks and safety scores over the "helpful assistant" behavior that made GPT-4 sticky. Outputs are shorter, refusals more frequent, and the model feels less useful for everyday writing tasks — even as benchmark numbers climb.
The pricing backlash has been particularly sharp. The Decoder framed it as "a new class of intelligence at double the API price" — and community commenters questioned whether OpenAI is "just finetuning existing models" rather than delivering architectural innovation.
The Adoption Data
Developer adoption data from early April 2026 adds useful context: 81% of developers still use ChatGPT/GPT models, but Claude's adoption has grown to 43% — reflecting that developers are actively diversifying rather than consolidating on one provider. The GPT-5.5 pricing increase may accelerate that bifurcation.
"The benchmark numbers are real. The price increase is also real. The question is whether the specific tasks you're running hit the benchmarks GPT-5.5 wins, or the ones it doesn't." — Handy AI
The Skeptics' Strongest Arguments {#skeptics}
It's worth taking the criticism seriously rather than dismissing it as benchmark illiteracy.
1. Benchmark-reality gap is widening. GPT-5 couldn't correctly count the r's in "raspberry" when it launched — a failure that has become shorthand for models that ace structured benchmarks while stumbling on casual tasks. The pattern hasn't fully resolved with GPT-5.5.
2. The "helpful assistant" regression. The GPT-5.2 backlash — users describing it as "robotic, boring, everything I hate about 5 and 5.1 but worse" — set a negative prior. GPT-5.5's safety and reasoning optimizations may preserve that tone shift even as agentic capabilities improve.
3. Price sensitivity at this capability tier. At $30/1M output tokens, costs approach a threshold where teams build hybrid routing — using cheaper models for simple tasks and reserving frontier models only for tasks that genuinely require them. The CodeRabbit benchmark analysis notes that for code review tasks, GPT-5.4 mini at a fraction of the price comes surprisingly close on standard PR review quality.
4. OpenAI's marketing framing problem. Describing a model as reaching "a new class of intelligence" when the primary use cases are incremental improvements to agentic benchmarks erodes trust. According to Gary Marcus's analysis, OpenAI has "a documented history of framing new models with macro-level language that exceeds eventual delivery."
Who Should Use GPT-5.5 {#who-should-use}
Use GPT-5.5 if:
- You're building autonomous agents that need to operate real computer environments (browser automation, desktop control, multi-app workflows)
- Your pipelines work with documents or codebases exceeding 256K tokens and need reliable retrieval
- You run terminal-heavy agentic coding tasks where the 13-point Terminal-Bench gap matters in practice
- You're already on OpenAI infrastructure and the token efficiency improvement justifies the price delta for your use case
Stick with Claude Opus 4.7 or wait if:
- Your primary use case is code review and real GitHub issue resolution (Opus 4.7 leads by 5.7 points on SWE-Bench Pro)
- You're running MCP tool-chain workflows requiring reliable multi-tool orchestration (Opus 4.7 leads by 3.8 points on MCP Atlas)
- Output cost matters — at $25 vs $30 per 1M output tokens, Opus 4.7 is 17% cheaper for output-heavy tasks
- You found GPT-5.x models less useful for everyday writing and ideation than GPT-4-era models
Use neither if:
- The task is achievable by GPT-5.4 mini or Claude Haiku 4.5 — the frontier tax isn't worth paying for simple generation or extraction
For workflow-based guidance on routing tasks to the right model, see the Autonomous AI Agents workflow and the Research Assistant workflow.
Early Verdict {#verdict}
GPT-5.5 is a genuinely capable model that leads on the specific benchmarks most relevant to autonomous agent work. The 82.7% Terminal-Bench 2.0 score, the OSWorld-Verified computer-use performance, and the long-context retrieval jump to 74.0% at 1M tokens are real improvements — not benchmark theater.
But the price doubling, the ongoing "helpful assistant" regression for non-agentic tasks, and the legitimate question of whether benchmark leadership translates to your specific workload make this a selective upgrade rather than a universal one.
The right frame: GPT-5.5 is the best model available today for autonomous computer use and long-context agentic pipelines. For everything else, route carefully.
FAQ {#faq}
Is GPT-5.5 available for free users? {#faq-free}
No. GPT-5.5 requires a Plus, Pro, Business, or Enterprise subscription through ChatGPT. The API is available to paid API customers at $5/$30 per million input/output tokens. GPT-5.4 remains available for free-tier users.
How does GPT-5.5 compare to GPT-5.4? {#faq-vs-5-4}
GPT-5.5 improves Terminal-Bench 2.0 by 7.6 percentage points (82.7% vs 75.1%), adds native omnimodal processing, significantly improves long-context retrieval (74.0% at 1M tokens), and introduces enhanced computer-use capabilities. The API price doubled from $2.50/$15 to $5/$30 per million input/output tokens.
What is GPT-5.5 Pro and when should I use it? {#faq-pro}
GPT-5.5 Pro is the highest-capability tier at $30/$180 per million input/output tokens. OpenAI positions it for the most demanding research and enterprise workloads. For most developers, standard GPT-5.5 provides the same architectural capabilities at one-sixth the output cost.
Does GPT-5.5 actually operate a computer? {#faq-computer-use}
Yes, with Codex integration. GPT-5.5 scores 78.7% on OSWorld-Verified, which tests real desktop and browser environment operation — not simulated tool-calling. It can see screen content, click, type, and navigate across applications. This is the most significant practical capability addition in this release.
Why did OpenAI double the API price? {#faq-pricing}
OpenAI attributes the price increase to GPT-5.5's substantially higher computational cost and claims 72% token efficiency improvement offsets the price change to approximately 20% real cost increase per task. Independent testing confirms the efficiency gain varies by task type — structured extraction tasks benefit most, while open-ended generation tasks may see closer to the full price increase.
Should I switch from Claude to GPT-5.5? {#faq-switch}
It depends entirely on your use case. GPT-5.5 leads on agentic computer use, long-context retrieval, and terminal-heavy workflows. Claude Opus 4.7 leads on SWE-Bench Pro (real code review), MCP tool orchestration, and is 17% cheaper on output. Most teams should route tasks to each model based on capability match rather than consolidating on one.
Sources & References {#sources}
- Introducing GPT-5.5 — OpenAI
- GPT-5.5 System Card — OpenAI Deployment Safety Hub
- GPT-5.5 vs Claude Opus 4.7: Which Model Wins for Agentic Work? — Beam AI
- GPT-5.5 Benchmark Results — CodeRabbit
- GPT-5.5 vs Claude Opus 4.7: Benchmarks & Pricing — LLM-Stats
- OpenAI's GPT-5.5 is here — VentureBeat
- OpenAI unveils GPT-5.5 at double the API price — The Decoder
- GPT 5's Rocky Launch Highlights AI Disillusionment — IEEE Spectrum
- Model Drop: GPT-5.5 — Handy AI
- OpenAI releases GPT-5.5 — TechCrunch
- Mythos-like hacking, open to all — The New Stack
- GPT-5.5 Real-World Coding Performance — MindStudio