DeepSeek V4 Review: Benchmarks, Pricing & The Distillation Controversy (2026)
By AI Workflows Team · April 25, 2026 · 12 min read
DeepSeek V4-Pro delivers GPT-5.4-class coding performance at $3.48/M output tokens — 87% cheaper than OpenAI. 1.6T parameter MoE model, 1M token context, Huawei Ascend native. But serious IP theft allegations from Anthropic and OpenAI shadow the launch.
What's Actually New in DeepSeek V4 {#whats-new}
DeepSeek V4 arrives as two distinct models targeting different use cases:
DeepSeek V4-Pro is the flagship: 1.6 trillion total parameters with 49 billion active parameters via Mixture-of-Experts (MoE) architecture. Pre-trained on 33 trillion tokens, it's the largest open-weight model available — exceeding Moonshot AI's Kimi K 2.6 by a significant margin.
DeepSeek V4-Flash targets speed and cost: 284 billion total parameters with 13 billion active, pre-trained on 32 trillion tokens.
Both models share four headline upgrades compared to V3:
1. 1M-Token Context Window {#context-window}
The jump from 128K to 1M tokens is the single most impactful architectural change for enterprise users. This enables processing entire codebases, multi-hour transcripts, or lengthy legal documents in a single context. The expansion is enabled by DSA (DeepSeek Sparse Attention) combined with token-wise compression that reduces the memory footprint of long-context inference.

2. Dual Thinking / Non-Thinking Modes {#thinking-modes}
Following R1's chain-of-thought success, V4 bakes this capability directly into both models. Users can toggle between:
- Thinking mode: Extended internal reasoning before output — ideal for complex math, code debugging, and multi-step planning
- Non-Thinking mode: Faster responses for straightforward queries where reasoning overhead would be wasteful
This matches (and arguably simplifies) the pattern OpenAI established with o3/o4-mini and Google with Gemini's "thinking" toggle.
3. Enhanced Agentic Capabilities {#agentic}
V4-Pro is explicitly designed as an agentic model. The API confirms integration with Claude Code, OpenClaw, and OpenCode agents. Both models support OpenAI's ChatCompletions API format and Anthropic's API format — making V4 a drop-in replacement for any stack already built on either platform.
The new model IDs are deepseek-v4-pro and deepseek-v4-flash. Legacy identifiers deepseek-chat and deepseek-reasoner will be fully retired on July 24, 2026.
4. Huawei Ascend Native Optimization {#huawei}
V4 is the first DeepSeek model designed from the ground up to run on Huawei's Ascend chip family (A2, A3, and 950 series). Huawei's CANN (Compute Architecture for Neural Networks) platform has been co-optimized alongside V4's architecture. This signals that DeepSeek's roadmap is now explicitly tied to Chinese domestic hardware, partially insulating the lab from U.S. semiconductor export restrictions.
DeepSeek V4 Benchmarks: Where It Wins and Where It Doesn't {#benchmarks}
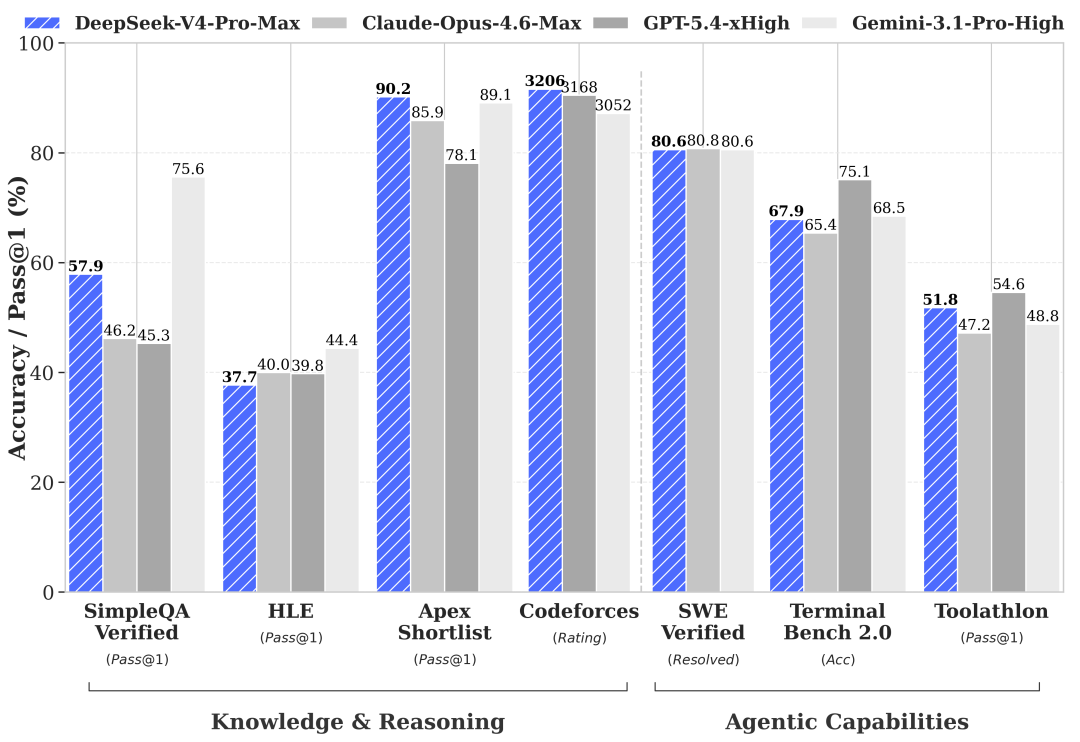
Knowledge & General Reasoning
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini-3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | ~87.5 | — | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HLE | 37.7 | — | 40.0 | 44.4 |
On general knowledge, V4-Pro roughly matches GPT-5.4 on MMLU-Pro and beats both Claude and Gemini on mathematical olympiad problems. However, it trails on HLE (Humanity's Last Exam), where Gemini-3.1-Pro leads at 44.4.
DeepSeek acknowledges V4 "falls marginally short of GPT-5.4 and Gemini 3.1 Pro" on world knowledge by roughly 3-6 months.
Coding Performance — V4's Clear Strength {#coding-benchmarks}
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| LiveCodeBench | 93.5 | <93.5 | <93.5 |
| Codeforces Rating | 3206 | 3168 | — |
| SWE-Verified | 80.6 | — | 80.8 |
| Terminal Bench 2.0 | 67.9 | — | 65.4 |
| MCPAtlas Public | 73.6 | — | — |
Coding is where V4-Pro genuinely shines. On SWE-bench Verified (real GitHub issue resolution), V4-Pro scores 80.6% vs Claude Opus 4.6's 80.8% — practically indistinguishable in production. The MCPAtlas score of 73.6 is notable: V4-Pro leads all tested models on MCP agentic workflows.
Pricing: The Number That Matters Most {#pricing}
The benchmark story is "roughly competitive." The pricing story is "dramatically different."
| Model | Input (Cache Hit) | Input (Cache Miss) | Output |
|---|---|---|---|
| V4-Flash | $0.028/1M | $0.14/1M | $0.28/1M |
| V4-Pro | $0.145/1M | $1.74/1M | $3.48/1M |
| GPT-5.4 | $2.50/1M | — | $15.00/1M |
| Claude Opus 4.6 | $5.00/1M | — | $25.00/1M |
V4-Pro's $3.48/M output represents an 87% discount vs. GPT-5.4 and a 91% discount vs. Claude Opus 4.6. Running 1 billion output tokens costs $3,480 with V4-Pro — versus $15,000 with GPT-5.4 or $25,000 with Claude Opus 4.6.
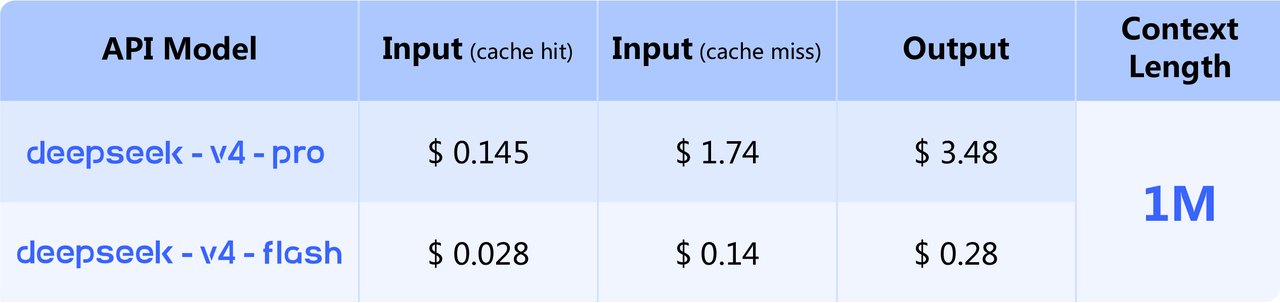
According to Fortune's analysis, further price reductions are expected as Huawei scales Ascend processor production. V4-Flash at $0.28/M output is already among the cheapest frontier-class options available.
The Distillation Controversy: What You Need to Know {#controversy}
The week before V4's release, the White House Office of Science and Technology Policy issued a statement alleging that "foreign entities, principally based in China, are engaged in deliberate, industrial-scale campaigns to distill U.S. frontier AI models."
This isn't a new accusation. In February 2026, Anthropic submitted a memorandum to Congress identifying three Chinese AI labs — including DeepSeek — as having "illicitly extracted Claude's capabilities" through distillation attacks. The alleged method: 24,000 fraudulent accounts generating over 16 million exchanges with Claude in violation of Anthropic's terms of service and regional access restrictions.
OpenAI made similar allegations to the House Select Committee on China, specifically accusing DeepSeek of "free-riding on capabilities developed by OpenAI and other U.S. frontier labs."
Distillation involves training a model on the outputs of a stronger model. The accusation: DeepSeek used Claude and GPT outputs as training signal to rapidly close a capability gap that would otherwise have required significantly more compute and original research.
China's foreign ministry dismissed the allegations as "groundless" and characterized them as "unjustified suppression of Chinese companies."
Why This Matters for Developers {#developer-implications}
- Legal risk: If Anthropic or OpenAI pursue legal action and succeed, API access could be disrupted.
- Benchmark validity: If V4's capabilities were partly bootstrapped from distillation of models that scored highly on these same benchmarks, the comparisons may be less independent than they appear.
- The innovation question: Ivan Su, senior equity analyst at Morningstar, said V4 is "competent" but "not as big a breakthrough as the rollout of R1." V4 is an incremental upgrade — not the paradigm shift R1 represented.
Real-World Community Reactions {#community}
The reception in technical communities has been more cautious than the initial R1 moment. Where R1 felt like a genuine surprise, V4 is being processed as an expected upgrade with a few recurring critiques:
- Text-only is a real gap: V4-Pro and Flash are text-only, unlike GPT-5.4 and Claude Opus 4.6 which offer vision. For vision-heavy workflows, this is a hard blocker.
- Preview status: V4 launched as a "preview" — no committed API SLA, rate limits may change.
- Huawei dependency questions: Some enterprise users flag supply chain concerns if geopolitical tensions escalate.
- Migration urgency: The July 24 deprecation of
deepseek-chatanddeepseek-reasoneris forcing immediate migration — arguably more disruptive than the model launch itself.
Getting Started with DeepSeek V4 {#getting-started}
The API is available immediately. Model identifiers:
# V4-Pro
model: "deepseek-v4-pro"
# V4-Flash (cost-optimized)
model: "deepseek-v4-flash"
Both models support the OpenAI ChatCompletions format:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "Solve this coding problem..."}],
max_tokens=4096
)
Important: Migrate from deepseek-chat and deepseek-reasoner to deepseek-v4-pro or deepseek-v4-flash before July 24, 2026.
Frequently Asked Questions {#faq}
Is DeepSeek V4 better than GPT-5.4?
On coding benchmarks, V4-Pro matches or leads GPT-5.4 — scoring 93.5 on LiveCodeBench and 80.6% on SWE-bench Verified. On general knowledge and multimodal tasks, GPT-5.4 maintains an edge. The more relevant question for most teams is cost: V4-Pro costs $3.48/M output tokens versus GPT-5.4's $15/M.
Is DeepSeek V4 open source?
Yes — both V4-Pro and V4-Flash are open-weight models available on Hugging Face. "Open-weight" means the model weights are released, not that training data or infrastructure is transparent. The distillation allegations relate specifically to training data provenance, not the weight release.
What happened to DeepSeek-R1?
R1 remains available but has been deprecated as a primary endpoint. The deepseek-reasoner identifier retires July 24, 2026. V4-Pro's built-in thinking mode is effectively the successor to R1's reasoning capabilities.
Does DeepSeek V4 support vision/images?
No. Both V4-Pro and V4-Flash are text-only models.
Should I be concerned about DeepSeek's data privacy?
DeepSeek is a Chinese company subject to Chinese data regulations, including laws that could require data sharing with government authorities. For enterprise workloads with sensitive data, this is a genuine consideration. Self-hosting the open-weight models on your own infrastructure is a viable mitigation.
The Bottom Line {#conclusion}
DeepSeek V4 is technically strong and aggressively priced — it narrows the gap with frontier closed-source systems, particularly in coding, at a cost structure that makes high-volume applications economically viable where GPT-5.4 or Claude Opus 4.6 simply aren't.
It is not a paradigm shift on the order of R1. The distillation allegations introduce legitimate uncertainty about how much of V4's capability was earned vs. borrowed. The text-only architecture leaves a gap for teams that need vision.
But at 87% cheaper than GPT-5.4 with genuinely competitive coding performance, V4-Pro will be a serious consideration for any developer making infrastructure decisions in 2026 — regardless of how the geopolitical drama plays out.
Sources & References {#sources}
- DeepSeek V4 Official Release Notes — DeepSeek API Documentation
- DeepSeek V4 Pro & Flash: Benchmarks and Pricing — OfficeChai
- DeepSeek Previews V4: Closes Gap with Frontier Models — TechCrunch
- DeepSeek V4: Price-Performance Analysis — Fortune
- US Sounds Alarm on AI Distillation as DeepSeek V4 Debuts — Asia Times
- DeepSeek V4 with Huawei Ascend Integration — Huawei Central