Claude Fable 5 Review: Benchmarks, Real-World Tests & Whether the Price Is Worth It (2026)
By AI Workflows Team · June 11, 2026 · 11 min read
Anthropic's Claude Fable 5 tops SWE-Bench Pro at 80.3% and is its most capable public model yet, but at $10/$50 it costs double Opus 4.8. We break down the benchmarks, real developer reactions, the safety fallbacks, and the 12-day free window.
Claude Fable 5 Review: Benchmarks, Real-World Tests & Whether the Price Is Worth It (2026)
TL;DR — Quick Verdict
Claude Fable 5 shipped on June 9, 2026, and it is the most capable model Anthropic has ever put in front of the general public. It tops nearly every benchmark Anthropic published — 80.3% on SWE-Bench Pro versus 69.2% for Claude Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. It is also slow, token-hungry, and priced at $10 per million input tokens and $50 per million output, exactly double Opus 4.8. The people who got early access agree on two things: it is the best coding model they have used, and you will feel it in your bill. If you run long, hard, agentic work like large migrations, multi-file refactors, or deep research, Fable 5 earns the premium. For everyday chat and light coding, Opus 4.8 is still the smarter buy.
This review covers what Fable 5 is, the official benchmarks, what real developers found in the first 48 hours, the safety classifiers that fall back to Opus, the pricing math, and the 12-day window where it is free.
What Is Claude Fable 5?
Claude Fable 5 is Anthropic's "Mythos-class" model made safe for general release. It is a single underlying model that ships in two forms: Fable 5, available to everyone with safety classifiers attached, and Claude Mythos 5, the same model with those classifiers lifted, restricted to cyber-defenders in Project Glasswing.
The model name is deliberate. Fable and mythos are cognate words — both mean "a thing that is told." A fable is for everyone; a myth is kept in the temple. Fable 5 is the version Anthropic decided the public could have.
Core specs:
- API model ID:
claude-fable-5 - Context window: 1M tokens, up to 128K output per request
- Pricing: $10 / $50 per million tokens (input / output)
- Thinking: adaptive only — the raw chain of thought is never returned
- Availability: Claude apps, the Claude API, AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry
Fable 5 is the successor to Claude Mythos Preview, the zero-day-hunting model Anthropic released to a closed group in April. At $10/$50, Fable 5 costs less than half what Mythos Preview did.
Claude Fable 5 Benchmarks
Anthropic's launch table shows Fable 5 and Mythos 5 at or near the top of every published evaluation. The two share the same weights, so the table reports the higher of the pair.
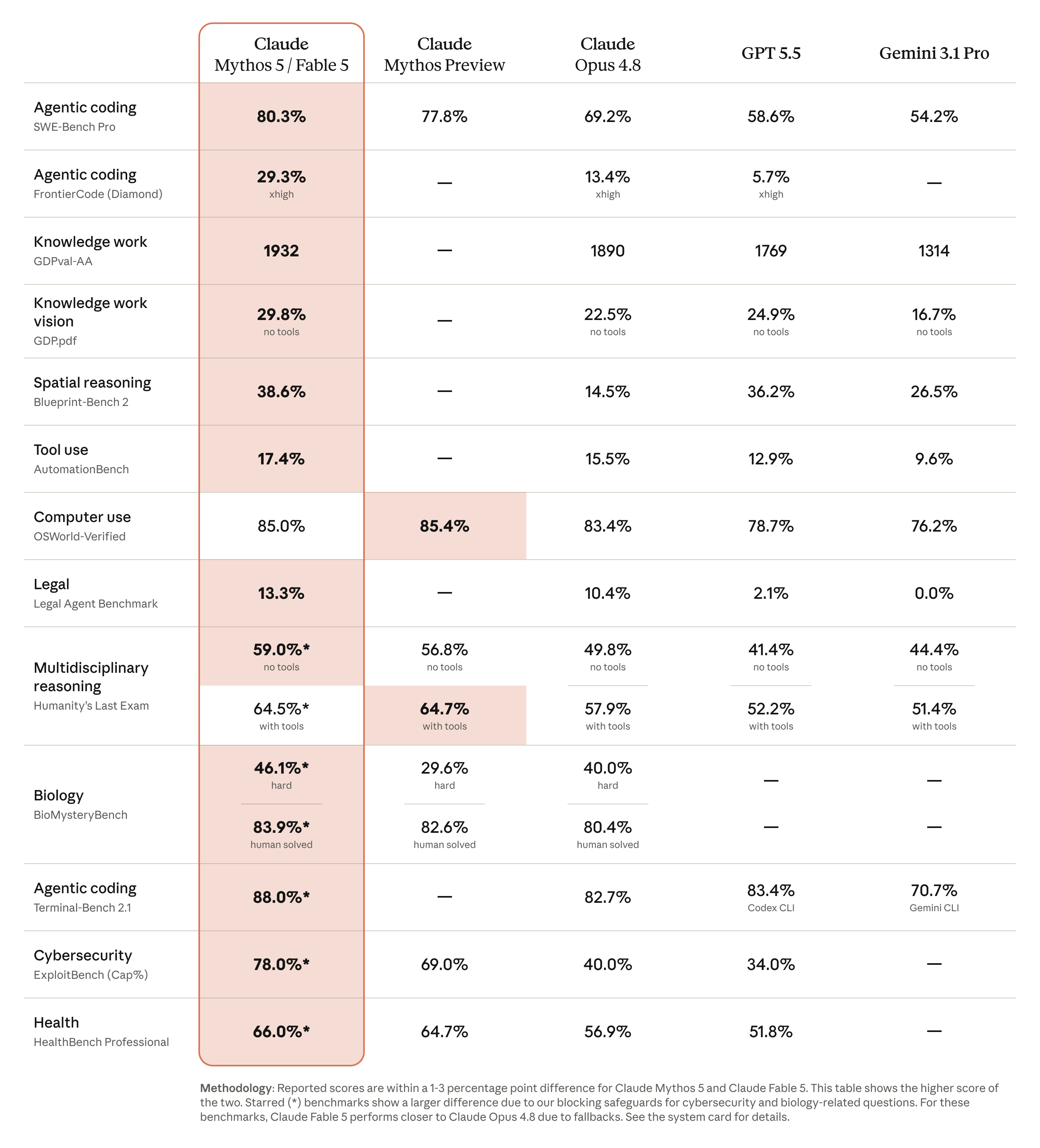 Official benchmark comparison: Claude Mythos 5 / Fable 5 vs Mythos Preview, Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. Source: Anthropic — Claude Fable 5 and Claude Mythos 5.
Official benchmark comparison: Claude Mythos 5 / Fable 5 vs Mythos Preview, Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. Source: Anthropic — Claude Fable 5 and Claude Mythos 5.
The headline numbers, public-facing where it matters:
- Agentic coding (SWE-Bench Pro): 80.3% — a clear lead over Opus 4.8 (69.2%), GPT-5.5 (58.6%), and Gemini 3.1 Pro (54.2%)
- Terminal Bench 2.1: 88.0%
- Multidisciplinary reasoning (Humanity's Last Exam, no tools): 59.0% vs 49.8% for Opus 4.8
- Knowledge work (GDPval-AA): 1932 vs 1890 for Opus 4.8
- Computer use (OSWorld Verified): 85.0%
One caveat matters for real use. The starred rows are Mythos 5 scores: cybersecurity (ExploitBench 78.0%), biology (BioMystery Bench 46.1%), and health. Because Fable 5's classifiers route those queries to Opus 4.8, the version you actually call performs closer to Opus on cyber and bio work. The frontier cyber numbers belong to the locked-down model, not the one in your account.
Coding capability versus cost
The most honest chart Anthropic published plots FrontierCode accuracy against dollars spent per task. Fable 5 (orange) pulls away from Opus 4.8 and GPT-5.5 on the hardest problems — but the x-axis is a log scale that runs to $20 a task.
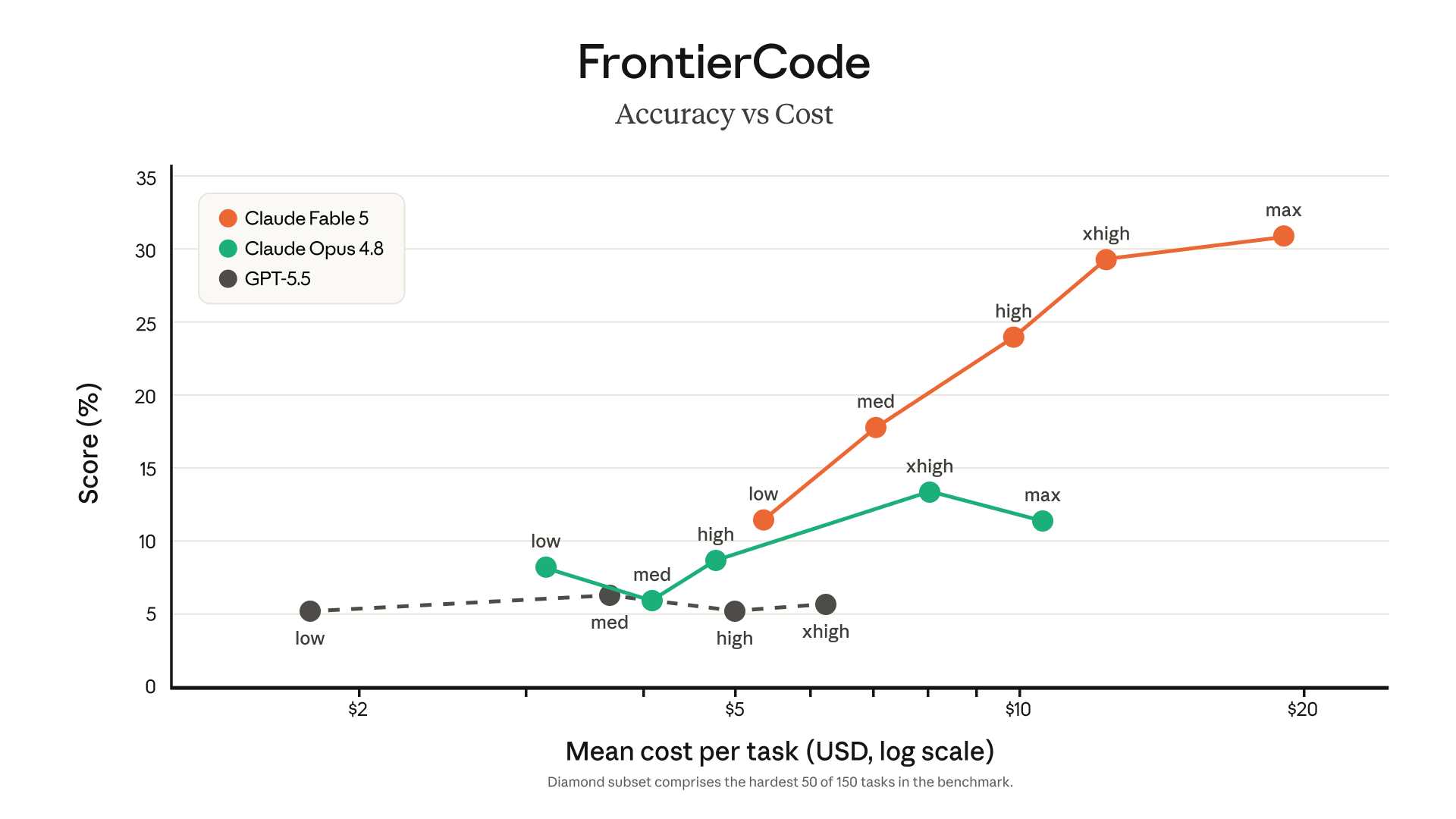 FrontierCode (hardest 50 of 150 tasks): accuracy vs mean cost per task, log scale. Source: Anthropic.
FrontierCode (hardest 50 of 150 tasks): accuracy vs mean cost per task, log scale. Source: Anthropic.
That single chart is the whole Fable 5 story in one image: more capable, demonstrably — and more expensive, demonstrably.
What Anthropic Showed Off
The launch leans on a handful of proof points that are genuinely hard to wave away:
- Stripe ran a codebase-wide migration on a 50-million-line Ruby codebase that Fable 5 finished in a single day. Anthropic says the same job would have taken a team more than two months by hand.
- Fable 5 beat the RPG Pokémon FireRed from start to finish using vision alone — raw screenshots, no maps, no navigation harness. Earlier Claude models needed a scaffold of helper tools just to play.
- Given file-based memory, Fable 5 improved its Slay the Spire performance three times more than Opus 4.8 did, and reached the final act three times as often.
- Using Mythos 5, Anthropic's protein-design team accelerated parts of drug design roughly tenfold, with the model producing strong candidates for 9 of 14 protein targets without human help.
These are vendor numbers, and you should read them as such. The more interesting evidence came from outside Anthropic.
What Real Developers Found in the First 48 Hours
Benchmarks tell you the ceiling. Practitioners tell you the experience. Here is what testers reported once the model was live.
Simon Willison — who is regularly given preview access to new models but, in his words, was not given early access to this one — called it plainly: "it's a beast." He pointed it at a Python library he had built the week before and asked it to research compiling full CPython to WebAssembly instead of MicroPython. A few prompts later he had a working wheel file. His one-line summary elsewhere: "slow, expensive and capable."
An engineer mid-database-migration on Hacker News was blunter: "It functions more like an actual engineer." Fable 5 reduced memory allocations in his code by 46×, found multiple bugs that Opus 4.8 and GPT-5.5 had introduced, and kept suggesting fixes to problems he hadn't flagged. His verdict: "this is the first model that feels like it's coming for my job."
Jamie Marsland of Automattic handed Fable 5 a screenshot and a URL and got back a fully editable WordPress block theme in one shot. "Yeah… this feels next level," he wrote.
数字生命卡兹克 (@Khazix0918), one of the most-followed AI builders in the Chinese developer community, ran it hard on his own products. He described Fable 5 as a "究极水桶模型" — an all-rounder with no weak side. A homepage-clustering feature he had failed to get out of Opus 4.8 across two sessions, Fable 5 designed, built, and shipped in 30 minutes using a time-decay scoring model, down to details like collapsing empty sections so the page falls back to a clean timeline. A month of scoring data that Opus 4.8 had summarized unremarkably came back from Fable 5 as a 78-minute, deeply detailed analysis he said gave him insights he had never spotted.
The catch he hit is the catch everyone hit: cost and speed. On a $200 Claude Max plan, three tasks — one of them unfinished — burned 73% of his five-hour quota. It was, he said, the first time he had ever run out of tokens. Dan Shipper of Every reported the same shape of problem, with Fable routinely chewing through 500K to 1M tokens on a single task and being best reserved for heavy jobs.
The Hacker News launch thread ran roughly 60/40 positive. The recurring theme from skeptics wasn't that Fable 5 is weak — it's that "slow, expensive, and capable" is a real trade-off, not a tagline.
The Safety Classifiers (and Their False Positives)
Fable 5 ships with something previous public Claude models did not: a set of classifiers that can decline a request outright. When the model detects a query about cybersecurity, biology and chemistry, or model distillation, the response is handled by Opus 4.8 instead, and you are told it happened. In the API, a declined request returns stop_reason: "refusal" as a normal HTTP 200, with the category that triggered it.
Anthropic says fewer than 5% of sessions trigger a fallback, and that the safeguards survived an external bug bounty of over 1,000 hours with no universal jailbreak found. The trade-off is over-blocking. The classifiers are tuned conservatively, and they catch harmless requests.
Real users felt the edge of that immediately. 卡兹克 asked Fable 5 to review his own codebase for security vulnerabilities — and was refused. "I can understand not letting me attack things," he noted, "but not letting me harden my own code still needs work." Anthropic acknowledges the false positives and says it intends to narrow the classifiers over time.
One more thing security-conscious teams should know: Fable 5 and Mythos 5 carry a mandatory 30-day data retention policy and are not available under zero-data-retention terms. Anthropic says the data is used only for safety, logged, and deleted after 30 days — but if your compliance posture depends on ZDR, that rules the model out today.
Pricing: Is Fable 5 Worth Double Opus 4.8?
Here is the decision most teams actually face.
| Claude Fable 5 | Claude Opus 4.8 | |
|---|---|---|
| Input (per 1M tokens) | $10 | $5 |
| Output (per 1M tokens) | $50 | $25 |
| SWE-Bench Pro | 80.3% | 69.2% |
| Context window | 1M | 1M |
| Best for | Long-horizon agentic work, hard migrations, deep research | Everyday coding, chat, high-volume pipelines |
At fleet scale the gap is concrete: a team pushing 50M input plus 10M output tokens a month pays about $1,000 on Fable 5 versus $500 on Opus 4.8. That $6,000-a-year difference only pays for itself if Fable's higher completion rate saves you more than the engineering hours it costs.
Token efficiency narrows the gap on the hardest work. One early customer reported Fable 5 finishing a frontier physics research task in 36 hours using roughly a third of the reasoning tokens GPT-5.5 needed across four days. On long, compounding tasks, fewer-but-pricier tokens can come out ahead. On a quick lookup or a boilerplate component, they never will.
The rule of thumb: reach for Fable 5 when task complexity is high, the context is long, or the work compounds across many steps. For everything else, Opus 4.8 or Sonnet 4.6 is the better economics. This is the same call you'd make when wiring a model into an autonomous AI agent workflow — match the model to the horizon of the task, not to the leaderboard.
The 12-day free window
There is a clock on this. From June 9 through June 22, 2026, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans. On June 23, Anthropic removes it from those plans; after that, using it requires usage credits. Anthropic says it intends to restore Fable 5 as a standard part of subscriptions once capacity allows. If you want to stress-test the model on real work before deciding whether to pay for it, the window is now.
How to Access Claude Fable 5
- In the Claude apps: select Fable 5 from the model picker (look for the "Included until June 22" tag on subscription plans).
- In Claude Code: Fable 5 is live as a model option for agentic coding sessions.
- Via the API: call
claude-fable-5. Note the request surface — adaptive thinking is always on, sampling parameters are removed, and an explicitthinking: {"type": "disabled"}returns a 400, so omit the parameter instead. - On cloud platforms: available on AWS, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry.
For a fuller picture of where Fable 5 sits against the rest of the field, see our frontier model comparison and the Claude tool profile.
Frequently Asked Questions
Is Claude Fable 5 better than Opus 4.8?
On capability, yes — Fable 5 beats Opus 4.8 across Anthropic's published benchmarks, including 80.3% vs 69.2% on SWE-Bench Pro. On value, not always. Fable 5 costs twice as much and runs slower, so Opus 4.8 remains the better pick for everyday and high-volume work.
How much does Claude Fable 5 cost?
$10 per million input tokens and $50 per million output tokens — double Opus 4.8. It is free on Pro, Max, Team, and seat-based Enterprise plans from June 9 to June 22, 2026, after which it requires usage credits.
What is the difference between Fable 5 and Mythos 5?
They are the same underlying model. Fable 5 ships with safety classifiers that block or reroute cyber, bio, and distillation queries to Opus 4.8. Mythos 5 has those classifiers removed and is restricted to Project Glasswing cyber-defenders.
Why does Claude Fable 5 sometimes refuse requests?
Its classifiers flag cybersecurity, biology/chemistry, and model-distillation queries and hand them to Opus 4.8. Anthropic tuned them conservatively, so they occasionally catch harmless requests — including, in one reported case, a developer asking Fable 5 to audit his own code for vulnerabilities.
Is Claude Fable 5 good for coding?
It is the strongest coding model Anthropic has released. Stripe used it to migrate a 50-million-line codebase in a day, and independent testers report it finding bugs other frontier models missed. The constraint is cost and speed, not capability.
Sources & References
- Anthropic — Claude Fable 5 and Claude Mythos 5 (official announcement, benchmark table and charts): https://www.anthropic.com/news/claude-fable-5-mythos-5
- Anthropic — Introducing Claude Fable 5 and Claude Mythos 5 (developer docs, pricing and API): https://platform.claude.com/docs/en/about-claude/models/introducing-claude-fable-5-and-claude-mythos-5
- Hacker News — Claude Fable 5 launch discussion: https://news.ycombinator.com/item?id=48463808
- Search Engine Journal — Claude Fable 5 "Feels Next Level" (Jamie Marsland test): https://www.searchenginejournal.com/claude-fable-5-feels-next-level/578538/
- 数字生命卡兹克 (@Khazix0918) — hands-on review thread on X.
Benchmark table and FrontierCode chart reproduced from Anthropic's official announcement, with attribution, for editorial commentary.